Schedule call
Schedule call
Why do we need infrastructure templating?
For modern cloud native environments, infrastructure templating is critical as it helps simplify the processes of infrastructure development and maintenance, in particular:
-
- Makes infrastructure development easier by defining functional borders.
- Enables to test the interoperability of components even if they contain different technologies.
- Provides for sharing infrastructure patterns with other team members.
- Makes it possible to ship infrastructure as part of the product.
- Allows split responsibilities between Platform and SRE teams.
- Enables to fully utilize GitOps approach for all infrastructure components.
Now, let’s explore the most common use cases of infrastructure templating and take a closer look at the benefits that it holds.
Infrastructure development and promotion
During the development process you need to have a pipeline to develop and promote some features from dev to stage and prod environments, the same way as you deploy and test your applications. Using common infrastructure templates and versionating through Git helps you do this and integrate with your existing CI/CD solution.
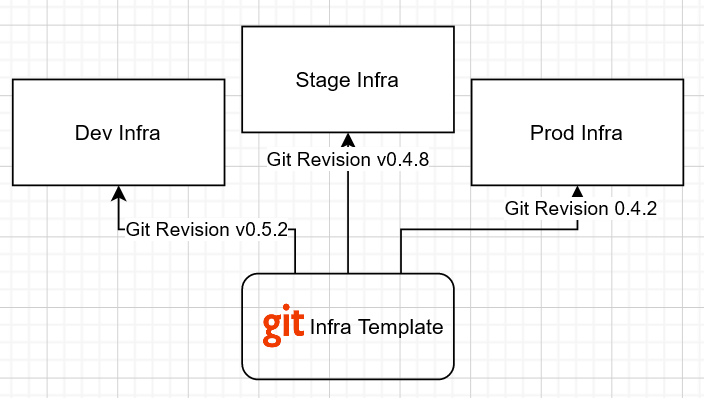
Infrastructure development process with the versioned template example.
Segregation of team responsibilities
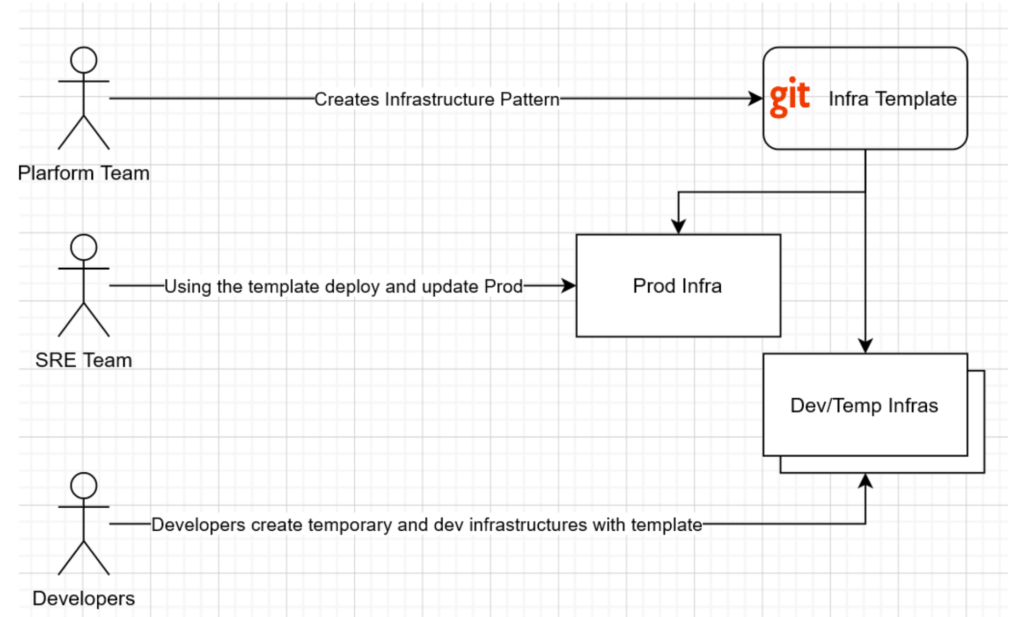
This becomes especially relevant when your company grows larger and you have several teams. The team responsible for creating infrastructure patterns (let’s call it a platform team) can provide these patterns as a complete Infra Template to an SRE team who actually deploys and operates production infrastructures. Beside that the same Infra Template can be used by developers and QA engineers to spawn temporary dev and test infrastructures:
Software shipment
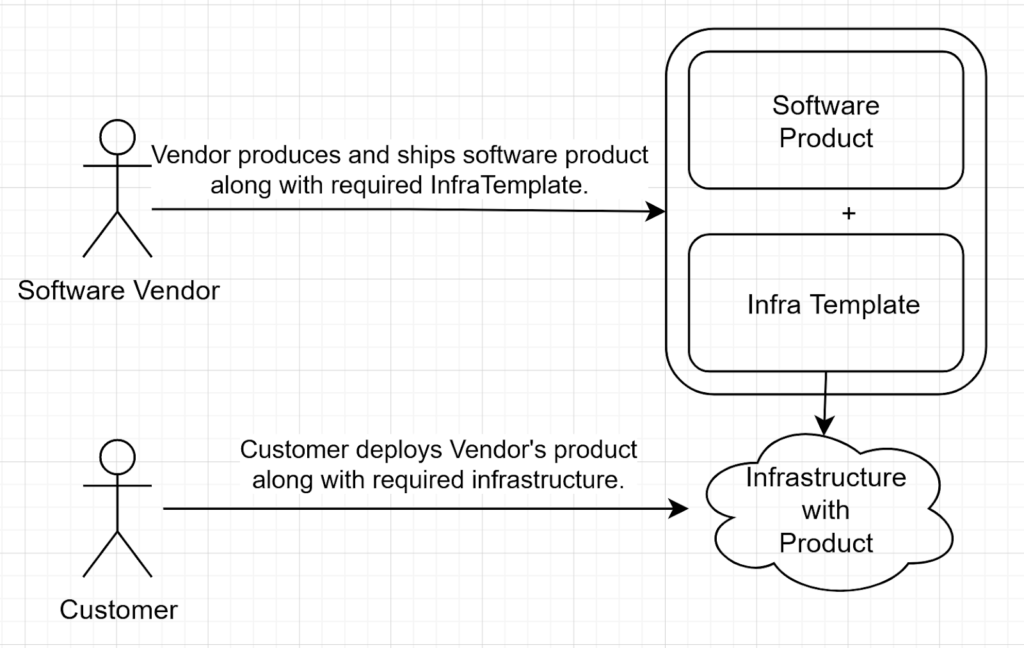
Complex business applications often require a complex infrastructure to be pre-deployed. In this case a vendor can ship their product along with the Infrastructure template in order to simplify the adoption process for the enterprise solution.
Template Market
Another use-case is when some engineer needs to deploy a new infrastructure for testing or exploring and wants all to be set in a few commands. He or she can choose a template from the Github project or from the marketplace, set the values and spawn the required infrastructure in minutes:

As we can see from the use cases above, templating can dramatically simplify the tasks of DevOps and SRE teams, including deployment and testing in complex environments. Now, what are the components of infra templates? We shall explore the building blocks required to create an infra template, proceeding from infrastructure layering.
Infrastructure Layering
Modern cloud native infrastructures may contain a lot of different layers. Based on our experience we identify the following of them:
-
- Networking Layer – VPC’s, Peerings, VPN’s, Security Groups and Routing.
- Permissions Layer – IAM roles and user policies.
- Infra and OS Layer – server instances provision, operating system settings.
- Data Management Layer – Relational and NoSQL databases, caches, file and object storages.
- Application Layer – container orchestration, application continuous delivery, business applications and workloads, infrastructure applications.
- Observability Layer – Metric logs and tracing applications and storages.
- Configuration Layer – Declarative configuration storage, infrastructure state storages, secret storages.
Let’s see how these layers could be covered with technologies and tooling.
Networking Layer
With the use of modern clouds most of the networking is covered by Software Defined Networks and Cloud API’s that enable users to declare a network as a code. There are two the most commonly used approaches here:
- To use Terraform modules designed to define cloud network for your project, for example: Terraform module which creates VPC resources on AWS
Terraform code and scripts for deploying a GCP Virtual Private Cloud (VPC).
Terraform Azure RM Module for Network
- When you need to define networking inside your container orchestration layer (ex Kubernetes) and there you have plenty of options using network plugins (CNI), for example: https://www.projectcalico.org/ or https://cilium.io/. In most cases the tools are delivered as Helm charts along with Kubernetes manifests.
Permissions Layer
Fine-grained permissions could be declared on different layers. Let’s check the most common ones.
The infrastructure permissions could be set with Terraform modules for IAM and Roles, for example: Terraform module which creates IAM resources on AWS, Terraform module to manage multiple IAM roles for resources on Google Cloud.
Or, if you need to set it in Kubernetes, the most common way to do this is to use native RBAC. Sometimes you also need to have external authentication like using OpenID Connect Tokens.
But sometimes you need to link permissions within Kubernetes to your cloud roles, and so you need to use technologies like AWS IRSA, Azure Managed Identities, GKE Workload Identity. In this case you need to combine Terraform modules with Kubernetes manifests, getting outputs from one technology and passing them to another.
Permissions and policy enforcement are mostly done using Open Policy Agent – an open-source engine for declaratively writing policies as code. OPA can be used for a number of purposes, including authorization of REST API endpoints, defining infrastructure policies by allowing or denying Terraform changes, etc.
Infra and OS Layer
As with previous layers, the infrastructure layer can also be declared with the Terraform modules: Terraform module Auto Scaling resources on AWS, Terraform module for configuring GKE clusters, Azure compute Terraform module, but sometimes you need to add extra configurations to your images with cloud-init and scripts, Hashicorp Packer or Ansible.
Data Management Layer
Most cloud providers support managed storages: AWS S3/EBS, GCP Cloud Storage, Azure file and blob storage. The same goes for Managed Databases: AWS RDS, Azure Cosmos DB, Google Cloud Databases. The most common way to declare them is with Terraform modules.
Application Layer
Cloud native applications can be divided into two groups:
Infrastructure Applications – are deployed along with an infrastructure, like Kafka, Service Mesh, Ingress Controller, GitOps Controller. These are generally deployed with Helm charts or with some sort of bash-scripts.
Business Applications – are mostly deployed with CI/CD tooling like Jenkins and GitLab. Business applications have their own lifecycle that is different from infrastructure applications.
Observability Layer
Monitoring and logging can be provided by the cloud itself like AWS CloudWatch or Google Stackdriver, or by an external vendor like Datadog. Most of these solutions support Terraform for configuration.
In a cluster tooling like EFK or Prometheus/Grafana is mostly deployed with Terraform or as a Helm chart.
Configuration Layer
The most common way to store configuration and infrastructure declarations is in the Git repo. This approach adds accountability and enables us to restore required configuration versions to a certain point of time.
Another thing to consider is that you need to keep the resulting infrastructure state after applying the configuration. As it could contain some sensitive data, it is better to use a different storage, like object storage or database.
For storing secrets and certificates you can use cloud specific storages like AWS SSM, Azure Vault or opt for external tooling like Hashicorp Vault or SOPS.
Conclusion
So let’s recap how we could describe a modern infrastructure using a specific set of tooling for each layer:
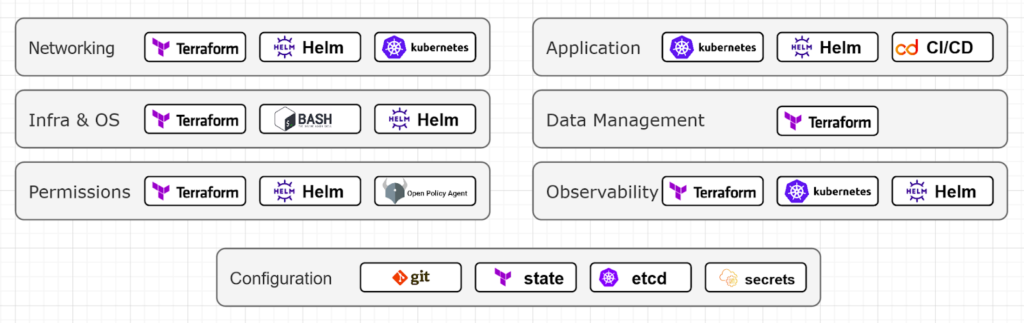
Infrastructure declaration by tools and layers.